
작은 메모장
31. Elastic 실습 본문
snort를 켠 후, db를 파이프라이닝할 파일 생성
생성에는 기초 코드를 바탕으로 코드를 생성
단, 경로는 환경에 따라 수정해야한다.
또, db로 접근할 계정명과 비밀번호 또한 여기 입력해야한다.
input {
jdbc {
jdbc_driver_library => "mysql-connector-java-5.1.36-bin.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/mydb"
jdbc_user => "mysql"
parameters => { "favorite_artist" => "Beethoven" }
schedule => "* * * * *"
statement => "SELECT * from songs where artist = :favorite_artist"
}
}

이후 logstash를 실행한다.

잘 가져오고 있는 모습을 확인할 수 있다.
즉, db에 저장하는 대로 elastic에 넘어가는 것이다.
이를 인덱스로 저장할 것이다.

저장이 되었으니, 이제 snort 실행을 할 것이다.


이 상태로, 트래픽을 하나 발생시켜본다.



snort에서 인덱스 연결까지 전부 해결했다.
이제 이를 처리할 elastic 설정을 할 것이다.
인덱스 패턴 설정부터 시작한다.
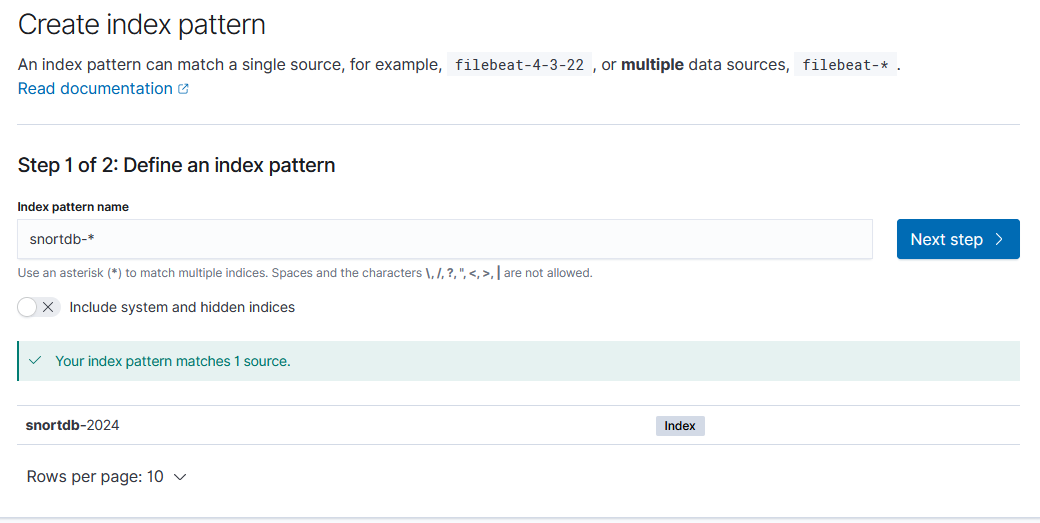

인덱스 패턴을 설정했으니, 데이터를 검색해보자.

자동으로 데이터를 불러오기 위해, 자동 새로고침을 10초 간격으로 설정한다.

데이터를 잘 가져오는지 유튜브에 wget을 요청해보자.


데이터를 잘 가져오는 모습을 확인할 수 있다.
트래픽을 추척하는데 있어 중요한 것 중 하나는 출발지와 목적지 정보다.
문제가 있다면, 두 개의 IP를 적용함에 있어 하나의 템플릿 파일에서는 사용하지 못한다는 것.

이와 같은 구조로 코드를 짜야하는데, 아래쪽의 geoip 정보가 위쪽의 정보를 덮어씌워버린다.
때문에 각각 따로따로 템플릿을 짜야한다.
인덱스 관리 창으로 이동한다.

템플릿을 생성할 조건에 맞게 이름과 패턴을 생성한다.

이와같이 매핑을 출발지와 목적지로 구분하여 나눈다.

설정을 마치고, 기존에 있던 인덱스는 제거한다.

그 후, filter 필드에 아래 내용을 추가한다.

logstash가 정상적으로 재시작하면, 트래픽을 생성해본다.

트래픽이 정상적으로 생성되는 것을 확인할 수 있다.
또한, 지역 정보도 정상적으로 불러오는 것을 확인할 수 있다.


이를 가지고 시각화를 해보자.



출발지와 목적지가 보이는 것을 확인할 수 있다.
'실더스 루키즈 교육' 카테고리의 다른 글
| 33. 인공지능과 데이터 2 (0) | 2024.02.06 |
|---|---|
| 32. 인공지능과 데이터 (0) | 2024.02.05 |
| 30. Elastic (0) | 2024.01.30 |
| 29. Splunk (0) | 2024.01.25 |
| 28. SQL, Snort 결과 최적화 (0) | 2024.01.24 |

