
작은 메모장
30. Elastic 본문
엘라스틱이란?
오픈소스 기반의 풀 텍스트 검색 엔진. 즉, 검색 엔진을 목적으로 제작된 프로그램
유연하고 탄력적인 데이터 처리를 지원
로그스태시
Logstash, 로그 수집 및 가공이 주 목적
순차적인 데이터 파이프라인을 제공하며, 다양한 데이터들의 입/출력 및 가공(필터) 지원

엘라스틱서치
Elasticsearch, 데이터 저장 및 검색이 주 목적. 사실상 엘라스틱의 본체다.
검색 라이브러리 루신 기반 검색 엔진, 데이터 저장 및 인덱싱을 지원
키바나
Kibana, 데이터 시각화 도구. splunk 생각하면 된다.
Splunk와 동일하게 웹 기반으로 데이터를 시각과 하며, 검색, 통계, 대시보드 등을 제공.

분산 데이터베이스
엘라스틱은 고유한 데이터베이스 구조를 가지고 있는데, 크게 3개의 구성요소가 있다.
- 노드 : 엘라스틱서치 실행 단위
- 인덱스 : 논리적 데이터 저장 단위
- 샤드 : 인덱스에 대한 논리적 디스크 파티션

관계형 DB와 엘라스틱 서치는 크게 다를게 없다.
몇몇 개념이 통합되거나, 기존 이름이 변경되는 등의 변화만 존재한다.

엘라스틱의 데이터베이스는 json 구조를 기본으로 두며, 이는 관계형 데이터베이스와 호환된다.

실습
제공받은 파일을 기준으로 elastic search, kinana, logstash를 설치한다.

최대 메모리 사용량을 조절한다. 최소 1기가, 최대 1기가로 설정한다.
설정 파일 경로는 elasticsearch > config > jvm.options
단순히 옵션 앞의 주석을 제거하면 된다.
elastic 세부 설정또한 변경한다.
설정파일 경로는 elasticsearch > config > elasticsearch.yml



elasticsearch\bin으로 엘라스틱을 실행시켜준다.


192.168.56.1:9200으로 접속하면, 다음 화면이 나오면서 접근이 성공한다.

같은 방법으로,kibana 또한 설정을 바꾼다.
설정 파일 경로는 kibana > config > kibana.yml


kibana를 실행한다.
실행 위치는 kinbana\bin
실행이 되고 192.168.56.1:5601으로 접속하면, 다음 화면이 나오면서 접근이 성공한다.

Management > Dev Tools로 이동하여 인덱스를 생성해보자.
PUT 명령어를 사용하여 인덱스를 생성한다.
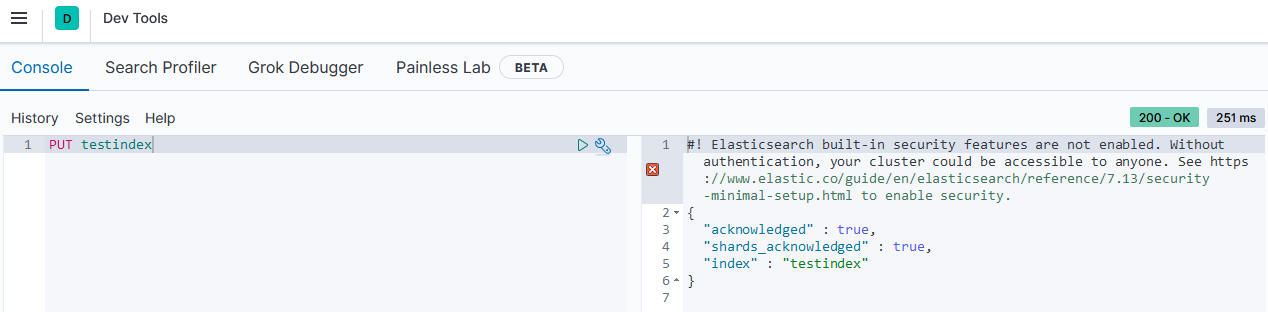
PUT과는 달리, GET은 인덱스를 조회하는 역할을 한다.

기존의 인덱스를 수정하고 싶을때도 PUT 명령어를 사용한다.

GET 인덱스로 조회를 할 때, 조건을 삽입하여 인덱스를 조회할 수도 있다.

기존의 인덱스를 삭제하고 싶다면, DELETE 명령어를 사용하면 된다.

만들어둔 인덱스 리스트를 보고 싶다면, Stack Management > Index Management로 이동하면 된다.

home에서 Upload file을 눌러 데이터를 올려보자.

제공 받은 apache-sample.log를 올려두고 확인해보자.
그럼 elastic이 자동으로 데이터를 구조화하여 불러온 것을 확인할 수 있다.

인덱스 생성 후, 추출을 진행한다.
인덱스를 생성할 때, 인덱스 패턴이라는 것을 따로 설정할 수 있을텐데, 쉽게 말해 같은 인덱스더라도 다른 인덱스처럼 사용하게 나눠놓는 것이다.
즉 A 라는 데이터를 A_1, A_2처럼 쓰는 느낌.



제공받은 nssm 파일을 사용할 것이다.
경로는 ..\nssm\win64

관리자 권한으로 cmd를 실행하고, 이 경로로 이동한다.

nssm 설치를 진행한다.

그럼 이렇게 창이 하나 뜨는데, 여기서 elastic 경로로 윈도우 서비스 등록을 진행할 것이다.
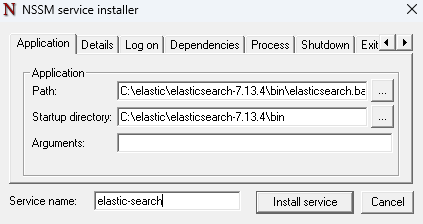
똑같이 kivana도 서비스 등록을 진행한다.
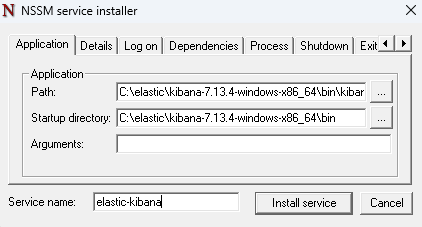
이제 하나하나 실행할 필요 없이, 윈도우 서비스 실행만으로 서비스 실행이 가능하다.

혹시라도 윈도우 서비스 실행으로 kibana 실행이 안된다면 의존성 설정을 직접 물려줘야 한다.
제공받은 secure-sample.log을 추출해보자.


추출을 했지만 문제가 하나가 있다.
바로 추출한 필드를 정확하게 인지하지 못해 그냥 필드1, 필드 2로 나타난다는 것.
이 설정은 더 자세하게 설정할 수 있는데, 처음 추출했을 때 Override Settings에서 변환 가능하다.
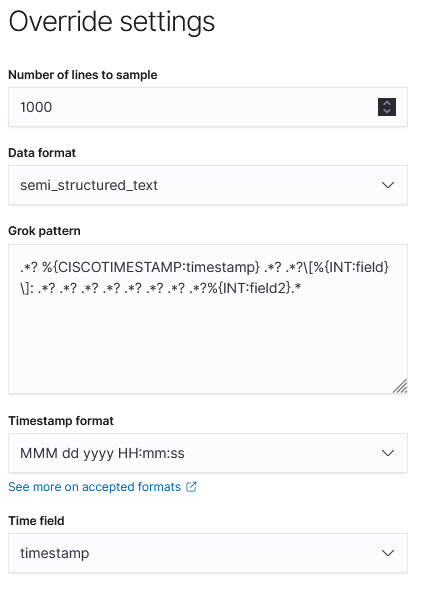
여기서 추출할 필드의 정규표현식과 함께 필드명 설정이 가능하다.
아직 정확하게 무엇을 추출해야할 지 모르기 때문에 그냥 설정을 넘어간다.
제공받은 iis-sample.log을 살펴봐도 필드 구분이 제대로 되지 않는 모습을 살펴볼 수 있다.
splelunk보단 데이터 필드 인지 능력이 많이 떨어지는 편.

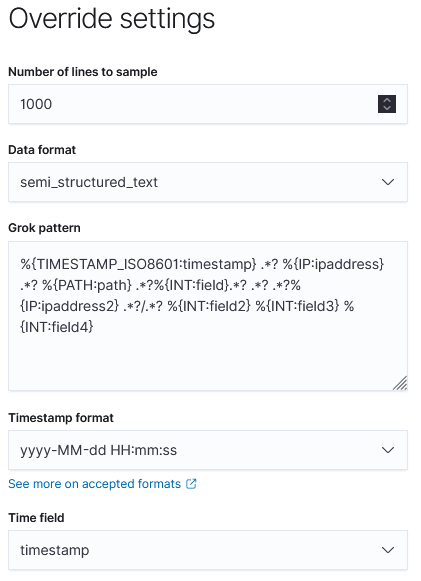
때문에 이 elastic을 사용하여 데이터를 분리할만한 데이터 형태는,
apache log나, 네트워크 log, csv정도가 있다.
저번에 엑셀로 가공한 apache_log를 csv로 저장하여 이를 추출하면, 정확하게 인식하는 것을 볼 수 있다.

마지막으로 logstash를 실행할 것이다.
설정 먼저 수정하자. 설정 파일 위치는 logstash > config > logstash.yml

또, 연결할 파이프라인을 새로 설정한다.
설정 파일 위치는 logstash > config > pipelines.yml
데이터 연동을 위한 환경설정을 해 줄 것이다.
일단 기본 elastic 폴더 밑에 환경파일을 만든다.

그 후, 아래와 같은 내용을 입력한다.
파이프라인 구조 형태는 공식 홈페이지를 따른다.

이상태로 한번 실행해보자.


지정된 경로에 있는 apache-sample.log파일을 잘 가져오면서, 각 파일에 있는 필드값을 가져오는 모습을 확인할 수 있다.
apache.conf 파일의 내용을 바꿔보자.
필드의 값을 필터링할 것이다.
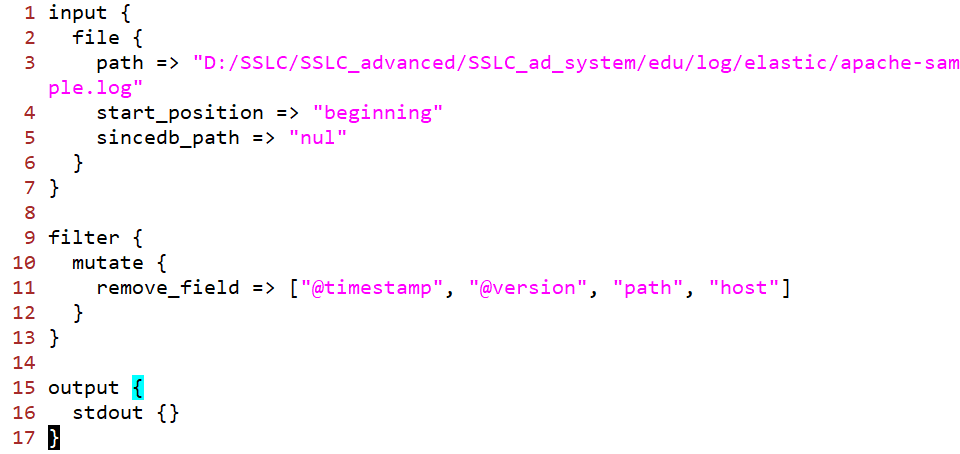
그러면 자동으로 재시작함과 이어 필터링된 필드 결과를 확인할 수 있다.

데이터 조회를 하기 위해 엘라스틱에 저장된 인덱스 패턴을 등록하는 과정이 선행되어야 한다.
즉, 내가 원하는 데이터만 뽑아내기 위해서는, 엘라스틱이 알아들을 수 있는 패턴을 등록해야한다는 뜻.
Management > Dev Tools로 이동하여 다음을 시행해보자.


정상적으로 데이터를 뽑아오는 것을 확인할 수 있다.
IPV4만 적어도 데이터를 뽑아오는 것이 신기방기한데, 사실 이는 오픈소스 상에서 미리 정의되어 있기 때문이다.
정의를 살펴보면 엄청나게 많고 복잡한 정규표현식이 적혀있음을 확인할 수 있는데, 이는 어떤 데이터를 넣어도 정확하게 인식하기 위해 이렇게 복잡하게 되어 있는 것이다.
필터 조건이 잘 인식하는 것을 확인하였으니, apache.conf에서 이 필터를 적용시키는 것을 해보자.
filter의 조건을 다음과 같이 변경하고, cmd를 확인해보자.


그럼 이렇게 apache 메시지 정보를 필터링하여 필드별로 잘 가져오는 것을 확인할 수 있다.
다른 필터 또한 삽입해보자. 아래와 같이 filter 값을 수정해준다.


입력했던 형식대로 데이터를 잘 가져오는 모습을 확인할 수 있다.
이제 적용할 파일을 전부 elastic에 업로드 해보자.
그냥 파일을 올리는 것이 아닌 상단에 했던 파이프라이닝을 사용하여 올릴 것이다.
경로를 원본 apache로그 파일로 수정한다.

그 후, 로그 데이터를 저장할 경로와 붙일 인덱스를 설정한다.

저장하게 되면, elastic에 정상적으로 저장된 모습을 확인할 수 있다.

다만, 데이터가 한 곳에 과도하게 쌓일 것을 우려한다면 일자별로 인덱스를 나눠 데이터를 분산시키는 방법이 있다.

이렇게 저장하게 되면 연도 정보를 기준으로 데이터가 저장된다.
즉, 2022년의 데이터와 2023년의 데이터는 다른 인덱스에 저장된다.
만들어둔 인덱스를 바탕으로 인덱스 패턴을 만들 것이다.
인덱스 패턴 생성으로 진입한다.
와일드카드를 사용하지 않고 그냥 2022 하나만 선택할 것이다.

시간 기준은 @timestamp를 기준으로 한다.

그 후, 검색으로 들어가 시간 정보를 적당히 조절하여 데이터를 살펴본다.

이런식으로 검색 조건을 넣을 수 있다.

검색할때 일반 필드와 키워드 필드가 나뉘어 있는것을 확인할 수 있는데,
이는 집계를 하냐 하지 않느냐를 나눠놓은 것이다.
단, 이 키워드 필드를 사용할 때는 주의해야할 점이 몇가지 있다.


이런식으로 인덱스를 기본으로 검색이 되는 것을 확인할 수 있으며
위와같은 검색어를 일반 필드로 검색할때는 검색이 불가능하다.
쉽게 말해, 키워드 필드는 와일드카드 등의 키워드 사용이 가능하다.
또 하나 조심해야할 점은, 키워드 필드는 인덱스 검색을 할 시 대소문자를 구분한다는 것이다.
일반 검색어는 대소문자를 전부 소문자로 바꿔 구분할 필요가 없지만, 키워드 검색은 대소문자를 반드시 구분한다.
이 두가지만 조심하면서 검색하자.
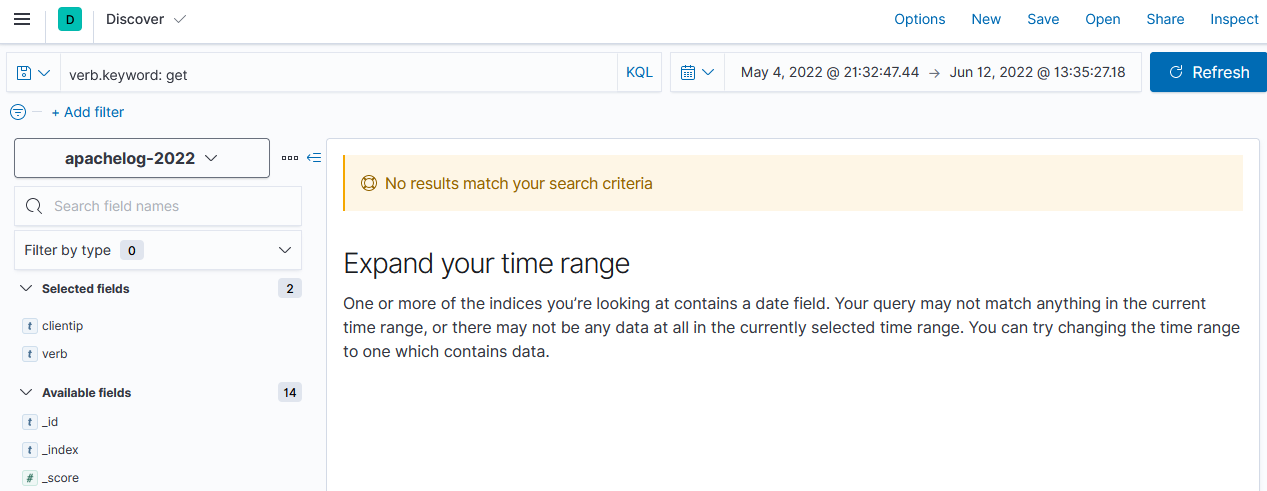
데이터 시각화를 하려면, Analytics > Visualize Library로 진입하면 된다.

여기서 Aggregation based를 누른다.
시각화할 종류는 원하는 종류로 선택한다.
여기서는 Line으로 설정하였다.
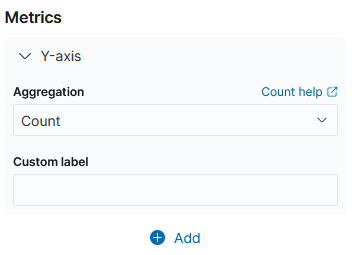
일단, Y축의 셈법은 여러가지가 있으나, 기본적으로 count를 사용한다.
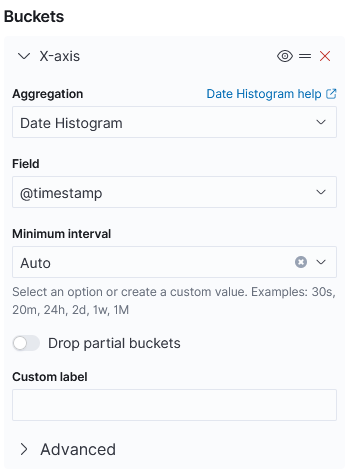
그리고 x축은 시간대별로 그래프를 만들 것이다.
또, 응답코드별로 데이터의 입력을 보기 위해, 데이터 추가 입력을 진행한다.
모든 설정을 마치면 Update 버튼을 누른다.
그럼 다음과 같은 그래프를 볼 수 있다.

데이터 시각화 종류를 변경하면 다음과 같은 표현도 가능하다.
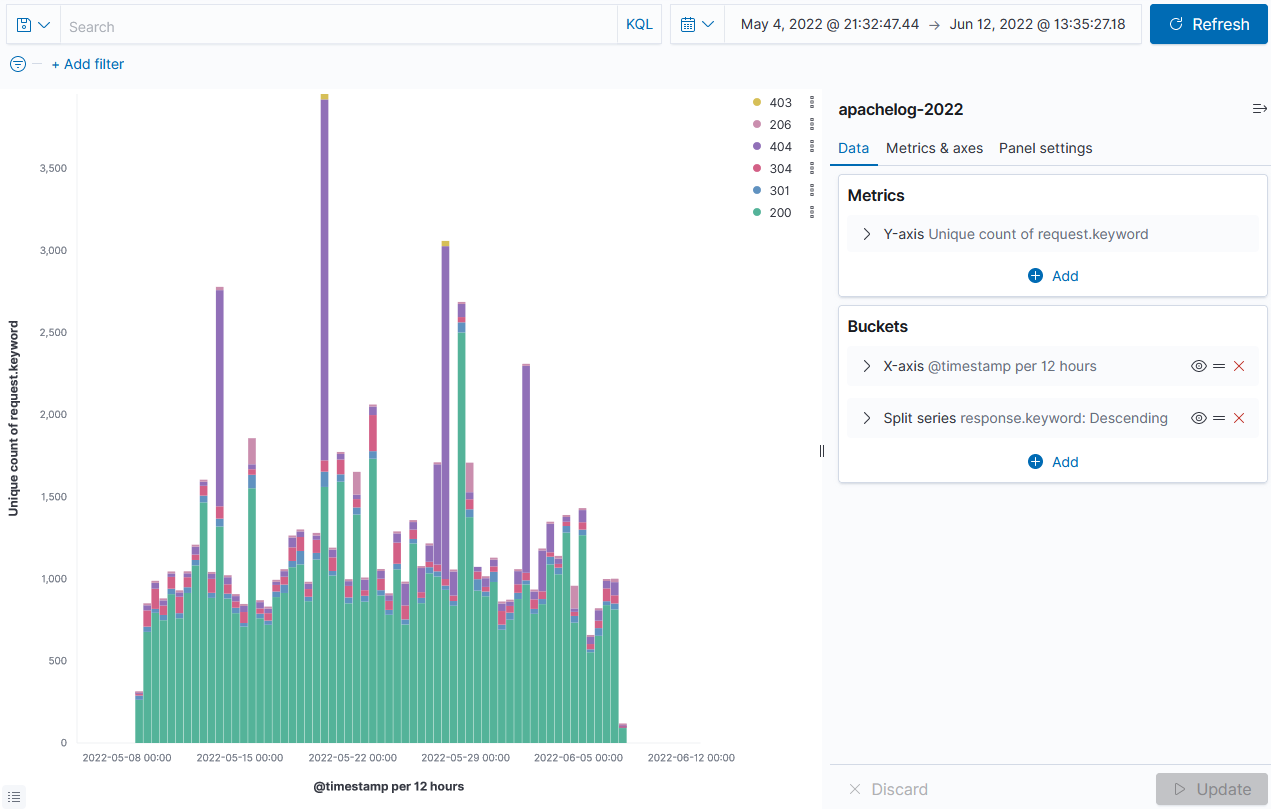
url 정보를 자세하게 뽑아내기 위해 파이프라이닝으로 데이터를 추출해 볼 것이다.
apache.conf 파일을 편집하여 아래의 내용을 추가한다.

이는 파이프라이닝 필터 안에 조건문을 삽입할 수 있다는 것이다.

url 정보가 정상적으로 분리된 것을 확인할 수 있다.
url 정보를 분리한 것은 좋은데, 특정 필드는 분리하지 못하는 현상이 일어난다.
이유인 즉슨, ?로 분리하는 필드가 아닌, .으로 분리하는 필드에 대해서는 처리를 못하기 때문.
.으로 분리하는 필드는 총 2종류인데, 끝에 파일이 존재하는 경우와 끝에 경로가 존재하는 경우 두가지가 있다.
이 둘을 처리하는 코드를 추가한다. 아래의 내용을 입력한다.


정상적으로 정보를 가져오는 것을 확인할 수 있다.
url에는 단순히 url 정보만 들어가있는 것이 아니다. 클라이언트에서 요구한 파라미터 정보 또한 존재한다.
이를 가져오는 코드는 Ruby 코드를 사용하여 내용을 완성할 것이다.
보통 파라미터 정보는 ? 밑에 존재하기 때문에, ?를 검사하는 코드 안에 해당 내용을 작성한다.


파라미터 정보를 잘 가져오는 것을 확인할 수 있다.
이제 필요할만한 정보를 얻었으니, 이를 elastic에 저장할 것이다.
단, 이미 저장되어 있는 인덱스의 이름으로 올릴 것이므로, 기존의 인덱스는 삭제하고 업로드를 진행한다.


재업로드가 된 것을 확인하였다.
이 인덱스를 시각화하여 표시해보자.

파라미터 길이 평균을 기준으로 시간대별 파라미터를 검색한 것이다.

여기에 응답코드까지 더하여 시각화를 표현하였다.
조금 더 개선된 시각화를 위해 위치정보를 추가해준다.
아래와 같이 파일을 수정한다. 단, 여기서 인덱스의 이름은 그냥 기본값으로 설정한다.


기본값으로 된 인덱스를 지정하기 위해, 인덱스 패턴을 생성한다.
이때, 인덱스의 패턴은 일반 Alias 패턴인 logstash로만 설정한다.

이제 지도 시각화로 이동해 만들어둔 인덱스를 기준으로 시각화를 한다.

또한, 툴팁을 수정하여 마우스를 올렸을 때 나오는 정보를 수정할 수 있다.

기존에 있는 인덱스를 전부 지우고, 통합 관리형 인덱스 패턴을 생성하여 시각화를 진행할 것이다.

여기서 템플릿 이름과 템플릿 패턴을 전부 설정한다.

전부 넘어가다가 매핑 과정에서 다음과 같이 설정한다.

그럼 이렇게 apachelog로 시작하는 모든 템플릿을 가지는 템플릿 패턴을 생성하였다.
이걸 이용하여 지리 시각화 정보를 전부 관리하게 된다.

이제 시각화에서 위경도 좌표를 정확하게 인식할 수 있을 것이다.

'실더스 루키즈 교육' 카테고리의 다른 글
| 32. 인공지능과 데이터 (0) | 2024.02.05 |
|---|---|
| 31. Elastic 실습 (0) | 2024.01.31 |
| 29. Splunk (0) | 2024.01.25 |
| 28. SQL, Snort 결과 최적화 (0) | 2024.01.24 |
| 27. PCRE (0) | 2024.01.23 |


