
작은 메모장
26. Snort 룰 본문
룰
Snort의 룰은 크게 두 부분으로, 헤더와 옵션으로 나뉜다.
헤더는 트래픽의 발생 주체 및 방향을 정의하고
옵션은 트래픽의 세부 특징을 정의한다.
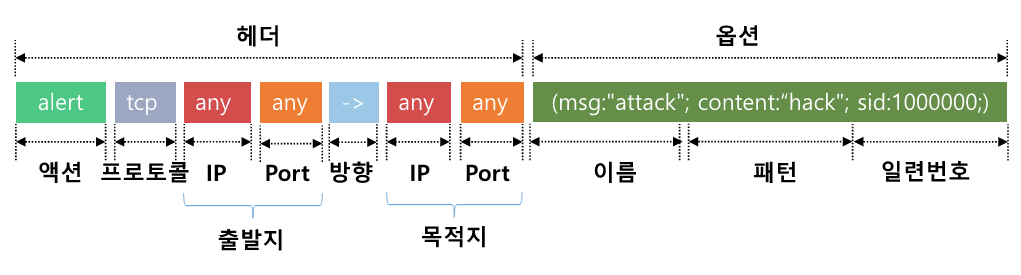
그럼 어딜 검사하는가? 이 또한 정말 간단하다.

오고가는 패킷에는 헤더와 페이로드가 존재한다.
이 룰 옵션은 헤더를 검사하는 옵션과 페이로드를 검사하는 옵션으로 나뉜다.
패킷 헤더 검사 룰 옵션
일단 자세한 사용법은 여기(http://manual-snort-org.s3-website-us-east-1.amazonaws.com/node33.html)를 참고하면 된다.
패킷 헤더 검사는 패킷 헤더의 물리적인 특성을 이용한 검사다.
옵션 종류에는 다음과 같은 종류가 있다.
- flow : 트래픽 방향 선택(SYN 플래그 기준)
- flowbit : 세션 추적
- flags : TCP flag bit 검사
- dsize : 페이로드 사이즈 검사
패킷 헤더 검사는 혼자서 쓰기에는 무리가 있다.
어디까지나 패킷의 물리적인 특성을 이용한 것이므로, 패킷의 신상만 보고 탐지 여부를 보는 것과 마찬가지다.
때문에 페이로드 검사와 같이 혼용하여 쓰는 경우가 대다수이고, 페이로드 검사보다 선행하여 미리 실행하면 성능 향상에 유리하다.
| [예시] alert tcp any any -> any any ([패킷 헤더 검사] [페이로드 검사]) |
flow
트래픽 방향으로 구분하여 검사하는 옵션이다.
SYN 플래그의 방향을 기준으로 Client와 Server를 나누는 특징이 있다.

위와 같은 상황에서, Snort는 Client를 0.3으로, Server를 204.205로 판단할 것이다.
flow 옵션의 플래그는 아래 4가지 종류가 있다.
- to_server : to_SYN 플래그 수신자, 즉 서버
- to_client : to_SYN 플래그 송신자, 즉 클라이언트
- established : 세션 수립 후
- not_established : 세션 수립 전
| [예시] flow: to_server; content: "aaa"; |
flow옵션의 단점은 Client와 Server 구분이 아주 정확하게 나뉘어 있는 네트워크에서만 사용이 가능하다.
P2P처럼 Server가 누구인지 판단하기 힘든 환경에서는 사용할 수가 없다는 단점이 있다.
flowbit
세션을 추적할 때 사용하는 옵션으로, 원하는 세션의 특정 부분을 찾아주는 옵션이다.
사용 방법이 조금 특이한데, 아래를 보자.
| content:”securecrt.html”; flowbits:set,‘세션 이름’; flowbits:noalert; |

| content:”VanDyke”; flowbits:isset,‘세션 이름’; |

flowbit에서 사용할 수 있는 플래그는 두가지로, set과 isset이 존재한다.
둘의 차이점은 아주 간단한데
set은 세션을 시작하려고 요청한 부분에서 조건에 맞는 부분을,
isset은 세션이 이어진 상태에서 조건에 맞는 부분을 탐색한다.
단순하게 플래그만 쓰면 끝나는 조건이 아니라, 플래그 뒤에 탐색할 세션 이름까지 적어야 사용이 가능하다.
flags
TCP는 흐름제어를 TCP 헤더 안에 플래그 필드에 작성하여 흐름을 제어하는 특징을 가지고 있다.
그 플래그 필드를 검사하는 것이 바로 flags 옵션이다.
옵션의 종류는 상당히 다양한데, 이 옵션이 종류가 바로 TCP 플래그의 종류를 그대로 따라간다.

빨간색으로 된 플래그들은 데이터를 주고 받을 때 가장 많이 사용되는 플래그들이다.
통상적인 세션에서 저 플래그 이외의 플래그를 거이 쓸 일이 없다는 뜻.
flag옵션을 사용할 때는 여러 옵션을 사용해도 좋지만, 가장 좋은 방법은 한가지 옵션으로만 검색하는 것이다.
통상적으로 검사할 요소가 많아지면 많아질수록 성능이 낮아지는 경향이 있다.
Push와 Ack는 일반적으로 꼭 붙어있는 플래그이기 때문에, 둘 다 옵션에 넣어 검사하게 되면 결과는 똑같은데 성능만 나빠지는 결과를 가져온다.
또, 일반적으로 패킷 검사 순서는 flag를 검사한 후, content를 검사하는 순서로 진행되어야한다.
flag 검사는 말 그대로 패킷 헤더의 특정 필드를 검사하기 때문에 성능 영향이 별로 없는 반면,
content 검사는 문자열을 그대로 검사하기 때문에 성능 영향을 아주 강하게 끼친다.
따라서 먼저 필요한 플래그만 걸러낸 후 content를 검사하면 더욱 효율적인 검사가 될 수 있다.
이는 마치 굵은 채로 먼저 거른 후에 촘촘한 채로 나머지를 걸러내는 느낌이다.
dsize
페이로드의 크기를 검사하는 옵션이다.
사용법은 아주 간단한데, 아래 예시를 보면 된다.
| 옵션 | 설명 |
| dsize:300 | 300byte |
| dsize:>300 | 300byte 초과 |
| dsize:<300 | 300byte 미만 |
| dsize:199<>301 | 199byte초과, 301byte미만 (200~300 byte) |
| [예시] alert tcp any any -> any any (msg:"flags-test"; dsize:<100; content:"HTTP/"; sid:1000004; rev:1;) |
threshold
패킷 발생량을 측정하는 옵션이다. 무작위 대입이나 무작위 공격을 막는 용도로 가장 많이 사용하는 옵션이기도 하다.
threshold는 사용법이 상당히 까다롭다. 이는 아래의 설명을 따른다.
| 분류 | 옵션 | 로그발생 단위 | 로그 발생 |
| 유형 | threshold:type threshold | 패킷 임계치(임계 시간 무시) | 5개 |
| threshold:type limit | 임계 시간 동안의 패킷 임계치(=발생 개수) |
7개 | |
| threshold:type both | 임계 시간 | 3개 | |
| IP 조건 | track by_src | 출발지 IP | |
| track by_dst | 목적지 IP | ||
| 패킷 발생량 | count | ||
| 시간 조건 | seconds |
헷갈릴법한 부분은 바로 threshold 유형으로, 종류는 크게 3종류가 있다.
limit:
limit은 지정한 seconds값 동안 count값만큼 까지만 로그를 탐지한다.
이게 무슨 소리냐면, 만약 탐지 조건을 다음과 같이 설정했다고 해보자.
| threshold: type limit, track by_src, count 7, seconds 30 |
이렇게 설정하면 snort는 30초동안 출발지를 기준으로 7번 로그까지만 로그를 남긴다.
10개, 100개가 들어와도 8번째 로그부터는 탐지하지 않는다.

일정시간동안 들어온 패킷중에서 딱 정해준 임계치까지만 탐지하므로, limit이라는 이름의 옵션이 된거다.
threshold:
threshold는 지정한 seconds값 동안 count값을 달성할 때마다 로그를 발생시킨다.
탐지조건을 다음과 같이 설정했다고 해보자.
| threshold: type threshold, track by_src, count 7, seconds 30 |
이렇게 설정하면 snort는 30초동안 7번의 패킷이 들어올 때마다 로그를 남긴다.
일정 시간동안 카운트가 될 때마다 로그를 찍는 것이다.

이러한 특성 때문에, threshold라는 이름의 옵션이 되었다.
both:
both는 limit과 threshold의 결합이다.
지정한 seconds값 동안 count값을 달성할 때 로그를 남기되, 단 한번만 남긴다.
| threshold: type both, track by_dst, count 7, seconds 30 |
이렇게 설정하면 snort는 30초동안 처음 7번의 패킷이 들어온 경우에만 로그를 남긴다.

두 탐지의 특성을 모두 적용하여 both라는 이름의 옵션이 된 것이다.
페이로드 검사 룰 옵션
일단 자세한 사용법은 여기(http://manual-snort-org.s3-website-us-east-1.amazonaws.com/node32.html)를 참고하면 된다.
패킷 페이로드 검사는 패킷의 페이로드, 즉 내용을 검사한다.
옵션 종류에는 다음과 같은 종류가 있다.
- content : 페이로드 전체 검사, 순수 문자열로만 검사
- uricontent : URL 검사, 순수 문자열로만 검사
- pcre : 페이로드 전체 검사, 정규 표현식으로 검사
content / uricontent
페이로드를 순수 문자열로만 검사하는 옵션으로,
전체를 검사할 것인지, url만 검사할 것인지의 차이를 두고 있다.
옵션 종류에는 다음과 같은 종류가 있다.


이 옵션을 사용한다면 주로 사용하는 값은 nocase, offset, depth, distance, within, fast_pattern 정도이며
관리하기 힘든 곳은 대충 nocase로 관리한다.
가령, 다음과 같은 룰을 적용했다고 하면
| ... content:“GET"; offset:0; depth:3; content:”rawdata”; distance:2; within:7; ... |

이런식으로 검사하게 된다.
pcre
Perl Compatible Regular Expression의 줄임말로,
쉽게 말해 정규표현식으로 검사하겠다는 옵션이다.
전체 페이로드 범위를 검사한다는 점에서 content와 동일하나,
정규표현식을 사용하여 룰을 적용한다는 것이 차이가 있다.
가령, .exe로 끝나는 파일을 검사한다고 하면,
content는 'a.exe'부터 'z.exe' 까지 노가다를 해야하는 반면,
pcre는 /[a-z]\.exe/ 라는 정규 표현식 하나로 축약해서 표현할 수 있다.
file_data
패킷의 내용에서 원하는 값을 찾는 옵션이다.
사용법은 간단한데, file_data 옵션을 선언 후, 바로 content로 찾을 내용을 지정하면 된다.
| [예시] alert tcp any any -> any any (msg:"file_data-test"; file_data; content:"MSIE 6.0"; sid:1000007; rev:1;) |
byte_test
특정 위치의 byte 크리를 검사하는 옵션이다.
사용하기가 조금 복잡한데, 문법은 아래와 같다.

무엇이 복잡한가? 싶을수도 있지만, 아래의 예시를 보고 이해해보자.
| [예시] content:”IDAT”; byte_test:4,>,400,-8,relative; |

위 명령을 해석하면 다음과 같다.
- content:”IDAT”;
패킷 내용중에서 IDAT의 문자열을 찾아서, - byte_test:4,
4바이트 값을 체크하되, - >,400,
그 값이 400보다 커야하고(bit 값 기준), - -8,
탐색 시작 위치를 IDAT 문자열의 끝에서 8바이트 뒤로 설정하며, - relative;
이 조건의 시작지점은 IDAT 문자열이 발견된 지점에서 시작한다.
위의 조건은 추가되거나 제거될 수 있으며, 대표적으로 byte_jump라는 옵션이 추가될 수 있다.
| [예시] content:”IHDR”; byte_jump:4,-8,relative; content:”tEXt”; distance:0; |

위 명령을 해석하면 다음과 같다.
- content:”IHDR”;
패킷 내용 중에서 "IHDR"의 문자열을 찾아서 - byte_jump:4,
탐색 지점을 4바이트 만큼 앞으로 이동하고 - -8,
탐색 시작 위치를 탐색 지점으로부터 8바이트 앞으로 뒤로 설정하며, - relative;
이 조건의 시작 지점은 IDAT 문자열이 발견된 지점에서 시작한다. - content:”tEXt”;
또한, 패킷 내용 중에서 "tEXt"의 문자열을 찾아서 - distance:0;
두 content(IHDR, tEXt) 사이의 거리가 0임을 검사한다. 즉 IHDR 뒤에 tEXt가 바로 이어져야 한다.
이런 식으로도 조건을 넣을 수 있다.
실습
제공받은 pcap 파일을 pscp를 사용하여 윈도우 -> 리눅스로 옮기는 작업부터 시작한다.

복사할 경로는 리눅스의 root 디렉토리로 복사된다.

잘 복사된 모습을 확인할 수 있다.
룰 파일 편집으로 새 룰을 추가해주자.
| vim /etc/snort/rules/local.rules |

barnyard2가 인식할 룰도 추가해주어야한다.
단, flowbits-set으로 설정한 탐지 규칙은 탐지를 하지 않고 라벨링만 해두는 것으로 설정했기 때문에 이 룰에 추가하지 않는다.(local.rules 파일에도 noalert로 설정했다.)
| vim /etc/snort/sid-msg.map |

이제 실행해보자.

barnyard2를 실행시켜놓고 snort는 기존 패킷 파일을 읽는 모드로 동작시킨다.

결과를 확인해보면, barnyard2에 결과가 하나 잡힌것을 확인할 수 있다.

아까 설정했던 sid 1000003번, 즉 flowbits-test 룰이 검출된 것을 확인할 수 있다.
DB에서도 아래의 SQL 문을 통해 확인해보자
| select a.timestamp, b.sig_name, inet_ntoa(c.ip_src), inet_ntoa(c.ip_dst), unhex(d.data_payload) from event a, signature b, iphdr c, data d where a.signature = b.sig_id and a.sid = c.sid and a.cid = c.cid and a.sid = d.sid and a.cid = d.cid and b.sig_name = 'flowbits-test' |

그럼 이렇게 딱 한개의 패킷이 검출된 것을 확인할 수 있다.
이 패킷을 우클릭 후 패킷의 내용을 확인할 수도 있다.
'Copy All Rows To Clipboard'를 눌러 메모장에 넣으면 그 내용을 확인할 수 있다.

또 다른 패킷을 검사해보자. threshold를 사용하여 검사해볼 것이다.
snort 룰 변경부터 한다.
| vim /etc/snort/rules/local.rules |

3초 동안 2번 이상 들어온 패킷을 잡아낸다는 조건으로 룰을 작성한다.
단, icmp 검출 조건은 1, 2번 룰과 중복되므로, 위의 두 룰은 주석처리를 한다.
이번에는 snort를 그냥 실행할 것인데, barnyard2를 쓰는 것이 번거롭기 때문이다.

-A console 옵션을 주어 snort가 패킷을 잡을 때 그냥 콘솔에 띄우도록 한다.

ping은 자기 자신으로 10번을 전송한다.

그럼 이렇게 5개의 옵션이 잡힌 것을 확인할 수 있다.
'실더스 루키즈 교육' 카테고리의 다른 글
| 28. SQL, Snort 결과 최적화 (0) | 2024.01.24 |
|---|---|
| 27. PCRE (0) | 2024.01.23 |
| 25. Snort 기초 설정 (0) | 2024.01.22 |
| 24. 개인정보보호법 개요 2 (0) | 2024.01.05 |
| 23. 개인정보보호법 개요 (0) | 2024.01.05 |



